本平台承担了程序设计与算法Ⅱ、编译技术、机器学习技术在内的5门课程的任务,包含树与二叉树相关算法实现等7个具体的实验项目,共20学时,如表所示。
表人工智能算法基础虚拟仿真实验项目
序号 |
虚拟仿真实验项目 |
学时 |
适合开设的课程 |
对应的平台 |
1 |
树与二叉树相关算法实现 |
2 |
程序设计与算法Ⅱ、编译技、机器学习技术与应用、数据挖掘、人工智能 |
人工智能算法基础虚拟仿真 实验平台 |
2 |
查找相关算法演示与实现 |
2 |
3 |
词法和语法分析和相关算法实现 |
4 |
4 |
ELF文件解析 |
4 |
5 |
朴素贝叶斯分类模型实现 |
2 |
6 |
决策树模型和逻辑回归模型实现 |
4 |
7 |
支持向量机与聚类算法实现 |
2 |
实验项目1:树与二叉树相关算法实现
内容简介:树和二叉树是一种非线性存储结构,是非常重要的数据结构,他比数组和链表更加的快速实用,也是很多高级结构的底层结构,如:堆内存结构。在树中查找数据项的速度和在有序数组中查找一样快,并且插入数据像和删除数据项的速度和在链表中一样快。通过一些方法可以用二叉树表示任意树。因此,本实验重点完成二叉树的基本操作,为人工智能方面的学习打下良好的算法基础。
实验界面:部分实验界面如图所示。
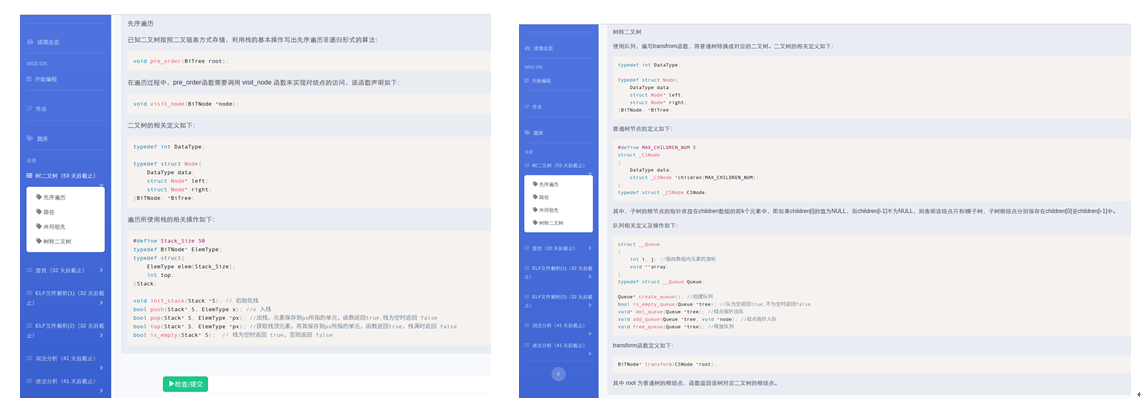
图 树先序遍历实验要求(截图) 图 树转二叉树实验要求(截图)
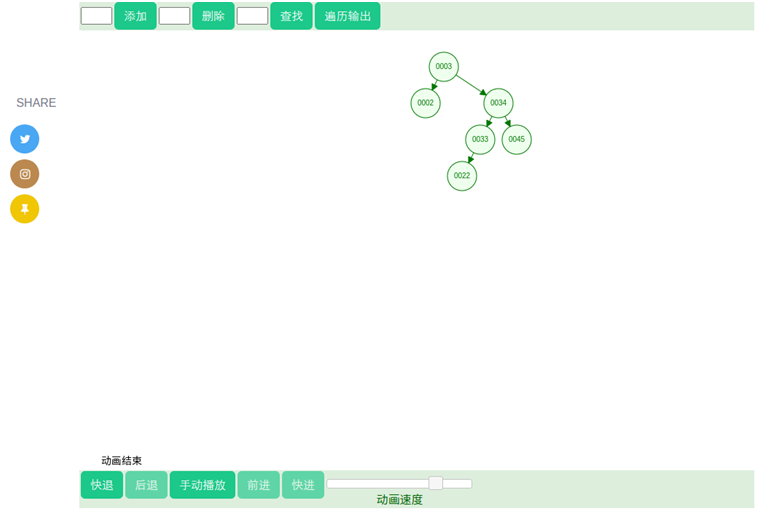
图二叉树插入动画演示(截图)
实验项目2:查找相关算法实现
内容简介:哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。记录的存储位置=f(关键字),这里的对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。平衡二叉树是一种二叉排序树,其中每个结点的左子树和右子树的高度差至多等于1。它是一种高度平衡的二叉排序树。
本实验将完成哈希表、元素添加、AVL元素添加等基本操作。
实验界面:部分实验界面如图所示。

图 哈希表创建实验要求(截图) 图 AVL元素添加实验要求(截图)
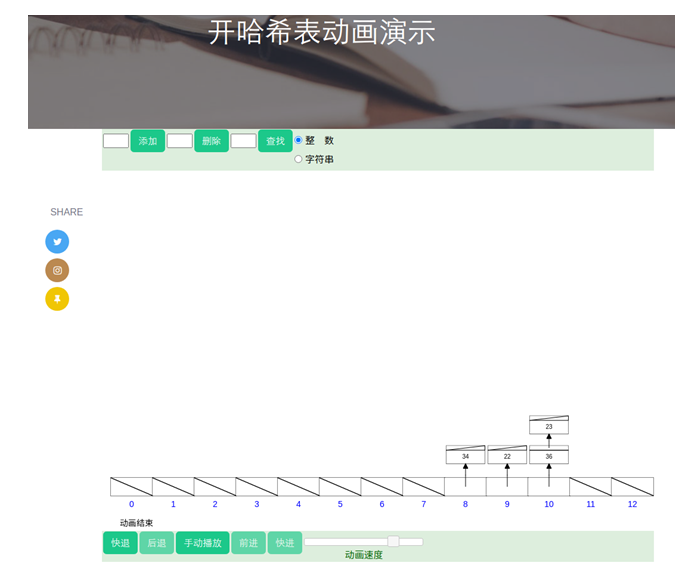
图哈希表插入动画演示(截图)
实验项目3:词法和语法分析器实现
内容简介:编译原理是计算机专业的一门重要专业课,旨在介绍编译程序构造的一般原理和基本方法。内容包括语言和文法、词法分析、语法分析、语法制导翻译、中间代码生成、存储管理、代码优化和目标代码生成。内容包括语言和文法、词法分析、语法分析、语法制导翻译、中间代码生成、存储管理、代码优化和目标代码生成。本次实验要求用C/C++完成词法分析器的设计与实现。即从左至右地对给定源程序(字符串)进行扫描,按照语言的词法规则识别各类单词,并产生相应单词的属性字。
实验界面:部分实验界面如图2-8、2-9所示。

图 词法分析器实验要求(部分截图) 图语法分析器实验要求(部分截图)
实验项目4:ELF文件解析
内容简介:ELF在计算机科学中,是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI)而开发和发布的,也是Linux的主要可执行文件格式。ELF文件格式对同学理解程序执行、链接器工作原理等都有着非常重要的作用。本次实验要求同学对ELF文件进行解析,并按实验要求实现解析相关函数。
实验界面:部分实验界面如图所示。

图 ELF文件节信息解析(部分截图) 图 ELF重定位信息解析(部分截图)
实验项目5:朴素贝叶斯分类模型实现
内容简介:朴素贝叶斯模型是传统机器学习领域中使用最为广泛的两种分类模型之一,发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。本实验让学生掌握贝叶斯分类器基本原理、掌握条件概率的计算方法、掌握python数据分析常用库pandas及其函数式编程,为人工智能方面的学习打下良好的算法基础。
实验界面:部分实验界面如图所示。

图 决策树示意(截图) 图 车载决策交互(截图)
实验项目6:决策树模型和逻辑回归模型实现
内容简介:通过训练数据构建决策树,可以高效的对未知的数据进行分类。逻辑回归又名对数几率模型,是离散选择法模型之一,属于多重变量分析范畴。本实验使学生掌握决策树算法原理和ID3决策树生成算法、决策树剪枝并编程实现ID3算法,要求学生实现评分卡预测信用风险的逻辑回归模型,使学生了解逻辑回归原理,掌握回归算法的优化器——随机梯度下降的原理,并编程实现逻辑回归算法。
实验界面:部分实验界面如图所示。

图 决策树结果可视化(截图) 图 模型ROC曲线(截图)
实验项目7:支持向量机与聚类算法模型实现
内容简介:支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,广泛应用于统计分类以及回归分析中,本实验要求学生在经典MINIST数据集上实现手写数字分类,从而理解支持向量机的核函数、优化方法等理论知识,并锻炼编码能力。K-means是最著名的划分聚类算法,简洁和效率使得他成为所有聚类算法中最广泛使用的算法。本实验要求学生实现K-means算法完成简单的坐标点聚类,使学生初步了解到非监督学习和K-means算法的实现原理。
实验界面:部分实验界面如图所示。

图 聚类结果(截图) 图 分类结果可视化(截图)

